KI im Medienbereich -Symposium in der Fachhochschule des Mittelstands


Am 30. November 2023 habe ich im Rahmen des "KI-Symposiums" der Fachhochschule des Mittelstands einen kleinen Einblick in KI im Medienbereich gegeben. Dieser Blogartikel dient als Kurzzusammenfassung der dort vermittelten Inhalte und zeigt die mitgebrachten Beispiele & Resultate der Arbeitsgruppe.
Spracherkennung
Am Beispiel von OpenAIs Whisper
Der erste Schwerpunkt meines Vortrags war die fortschrittliche Technologie der Spracherkennung, die durch künstliche Intelligenz neue Dimensionen erreicht hat. Hier stellte ich insbesondere das Modell "Whisper" von OpenAI vor.
Whisper hat sich als eines der besten Modelle für Spracherkennung etabliert. Es ist kostenlos & lokal nutzbar, beispielsweise über die App "Mac Whisper", und bietet eine beeindruckende Genauigkeit. Die Pro Version von Mac Whisper bietet weitere Vorteile wie z.B. die Batch-Transkription, erweiterte Modelle, DeepL Übersetzungen, Kundensupport etc. (siehe: MacWhisper). Diese Technologie erlaubt es, Sprachaufnahmen präzise in Text umzuwandeln, was zahlreiche praktische Anwendungen ermöglicht. Neben der Möglichkeit das Modell lokal zu nutzen, kann man auch auf die API von OpenAI zugreifen (siehe Blogartikel: Sprachnotizen in Aufgaben verwandeln: Ein Guide zur KI Automatisierung mit OpenAI, Dropbox und Zapier).
Praktische Anwendungen und Nutzen
Die Anwendungen für verbesserte Spracherkennung sind vielfältig. Einige Beispiele sind:
- Podcast Transkripte: Die Erstellung von Transkripten für Podcasts wird vereinfacht, was die Zugänglichkeit und Verbreitung des Inhalts verbessert. Zum Beispiel um Kapitelmarker zu setzen oder Beschreibungen, Tags etc. zu verfassen. Auch das Erstellen von Prompts für Beitragsbilder über Bildgenerierungs-KIs sind denkbar.

- YouTube Transkripte: Inhalte von YouTube-Videos können transkribiert und für weiterführende Analysen genutzt werden.
- Spracherkennungs Produkte: Diverse Produkte welche Telefonate, Meetings und Vorträge transkribieren bieten Möglichkeiten für Analysen, Zusammenfassungen und visuelle Darstellungen in Form von Mindmaps (siehe: Produkt PlaudeAI).
YouTube Transkripte zu ChatGPT senden
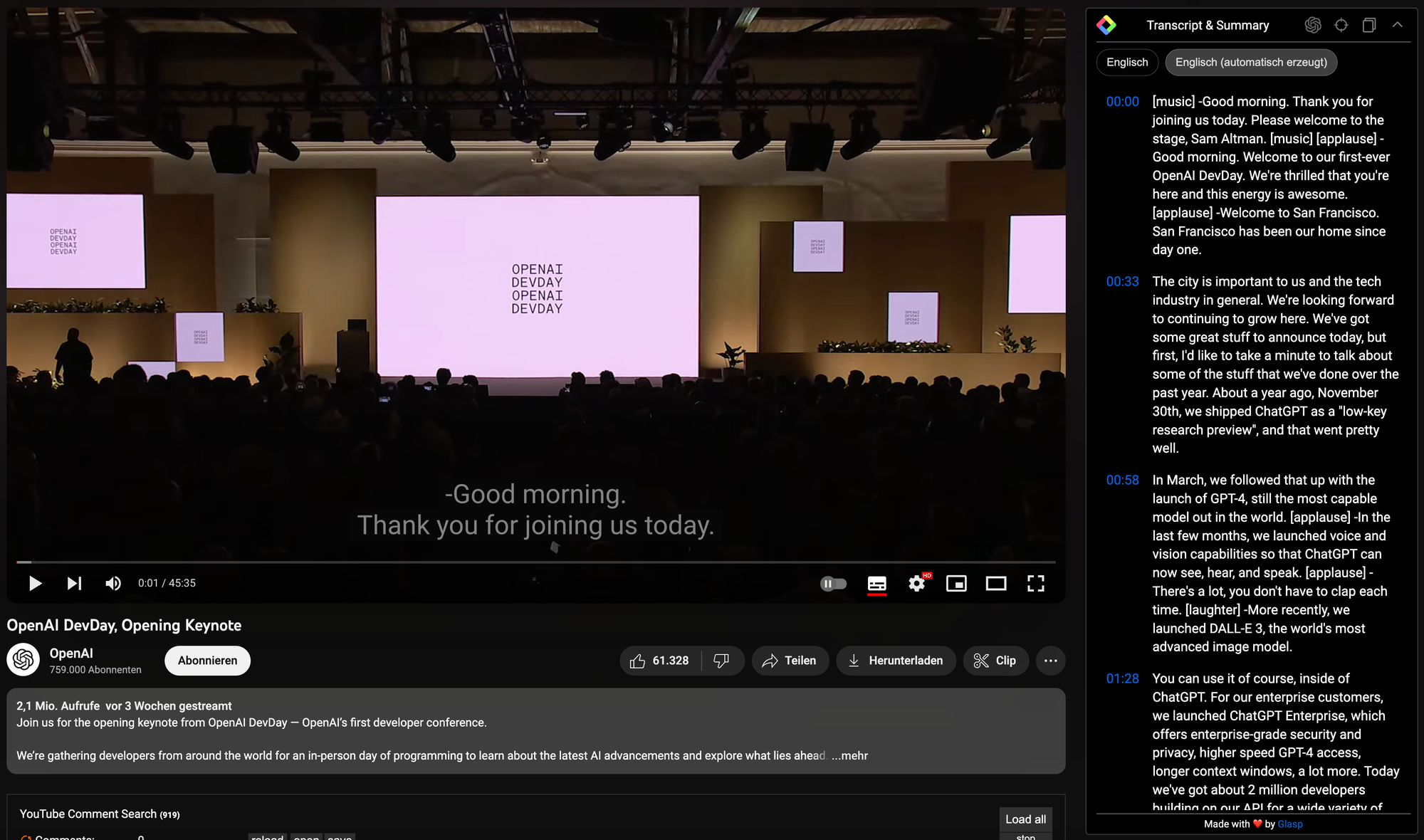
An dieser Stelle ein Tipp zur Weiterverarbeitung von YouTube Transkripten. Der Anbieter Glasp bietet eine Chrome Extension mit dem Namen "YouTube Summary" an (siehe: YouTube Summary with ChatGPT & Claude). Hier kann man von YouTube automatisch generierte Untertitel mit einem selbst formulierten Prompt an ChatGPT übermitteln.
Für diese Anwendung / Transkripte im Generellen habe ich einen Prompt formuliert, welcher mir den Inhalt strukturiert zusammenfasst, die Kernaussagen herausschreibt, Empfehlungen & Quellen notiert, diverse Analysen anfertigt und Fragen sowie Antworten formuliert.
Ich möchte, dass du das folgende Transkript analysierst und die folgenden Aufgaben strukturiert erledigst.
Bitte separiere jede Aufgabe mit Trennlinien und markiere wichtige Punkte fett durch hervorgehobene Textstile. Alle Antworten bitte auf Deutsch.
Stichpunkte: Fasse das Transkript kurz in strukturierten Stichpunkten zusammen.
Kernaussagen: Was sind die Kernaussagen aus dem Transkript und was kann ich daraus lernen?
Empfehlungen & Quellen: Liste alle Empfehlungen und genannten Quellen in einer Tabelle auf (Tabellenüberschriften: Kategorie, Empfehlung/Quelle, Kontext).
Detaillierte Zusammenfassung: Verfasse eine umfangreiche, strukturierte Zusammenfassung in tabellarischer Form (Tabellenüberschriften: Abschnitt, Beschreibung). Markiere wichtige Worte fett.
Analysen: Analysiere das Transkript unter Berücksichtigung verschiedener Perspektiven. Dies kann Folgendes umfassen: Sentimentanalyse, rhetorische Analyse, Themenanalyse, Sprachstil-Analyse, Analyse der Argumentationsstruktur, statistische Analyse, Analyse von Quellen und Referenzen, Vergleichsanalyse, soziokulturelle Analyse und Visualisierungsanalyse. Berücksichtige Fragen wie die Kompetenz und Konkretheit des Inhalts. Fertige Statistiken an und weise auf Besonderheiten hin.
Mögliche Fragen & Antworten: Was könnte ich nach dem Transkript für Fragen haben, und was sind die Antworten darauf? Formuliere mindestens 8 Fragen und deren Antworten.
NEXT STEPS: Wenn ich mich noch mehr mit dem Thema auseinandersetzen möchte, was könnte ich machen bzw. wonach könnte ich suchen? in German.
Das kann dann z.B. so aussehen:
Zukunftsausblick und Potenziale
Die Zukunft der Spracherkennung verspricht eine noch engere Integration in unseren Alltag. Von der Automatisierung von Hotlines bis hin zur Unterstützung in der professionellen Medienproduktion, die Möglichkeiten sind nahezu unbegrenzt. Insbesondere in der Verbindung mit anderen KI-Technologien wie ChatGPT eröffnen sich spannende neue Wege der Interaktion und des Informationsmanagements.
Sprachsynthese
Am Beispiel von Elevenlabs.io
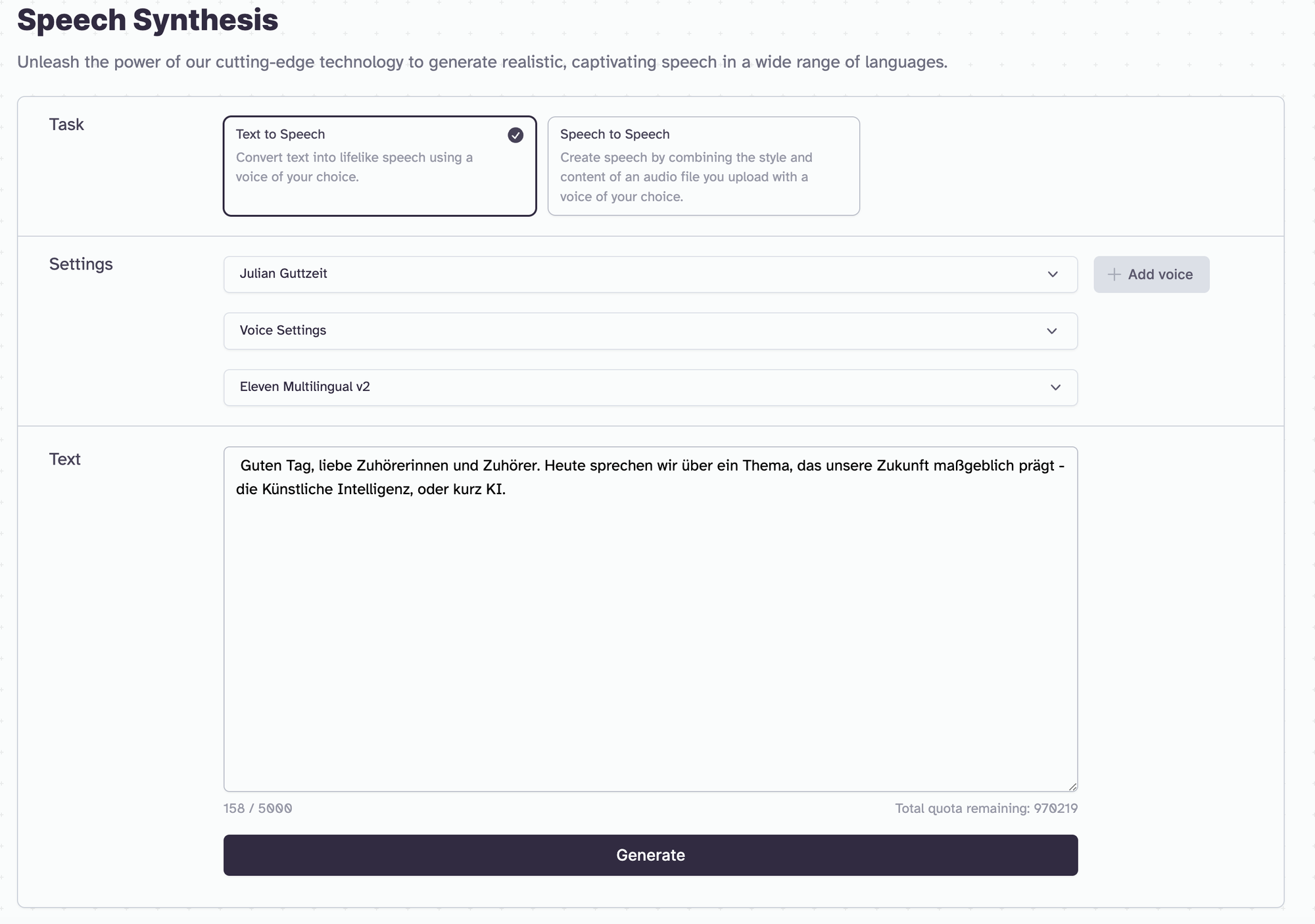
KI-Sprachsynthese bezieht sich auf die Technologie, die geschriebenen Text in gesprochene Sprache umwandelt. Diese Technik nutzt künstliche Intelligenz um reale Stimmen zu kopieren oder menschenähnliche Stimmen von Grund auf zu erzeugen. In meinem Vortrag gingen wir die Möglichkeiten der Plattform Elevenlabs durch.
Die Technologie ermöglicht es mit nur 30 Sekunden (bestenfalls qualitativ hochwertigem) Stimm-Material beeindruckende Ergebnisse zu erzielen. Dieses "Instant Cloning" (schnelle Verfügbarkeit bei kleinem Modell) überrascht durch seine Klangqualität, wobei das "Professional Voice Cloning" (4 Wochen Berechnung bei großem Modell) für noch exaktere Ergebnisse sorgt.
Ein bemerkenswerter Aspekt ist die Effizienz und Zugänglichkeit dieser Technologie: Innerhalb einer Minute kann eine Stimme geklont werden. Zudem gibt es bisher kaum Einschränkungen in der Art des generierten Inhalts. Diese Leistungsfähigkeit wirft jedoch ernsthafte Fragen hinsichtlich der Kontrolle und ethischer Bedenken auf.
Zwar hat das "Professional Voice Cloning" einen Sicherheitsmechanismus verbaut, welcher erfordert, dass man sein tonales Einverständnis gibt, das "Instant Cloning" hat dies jedoch nicht!
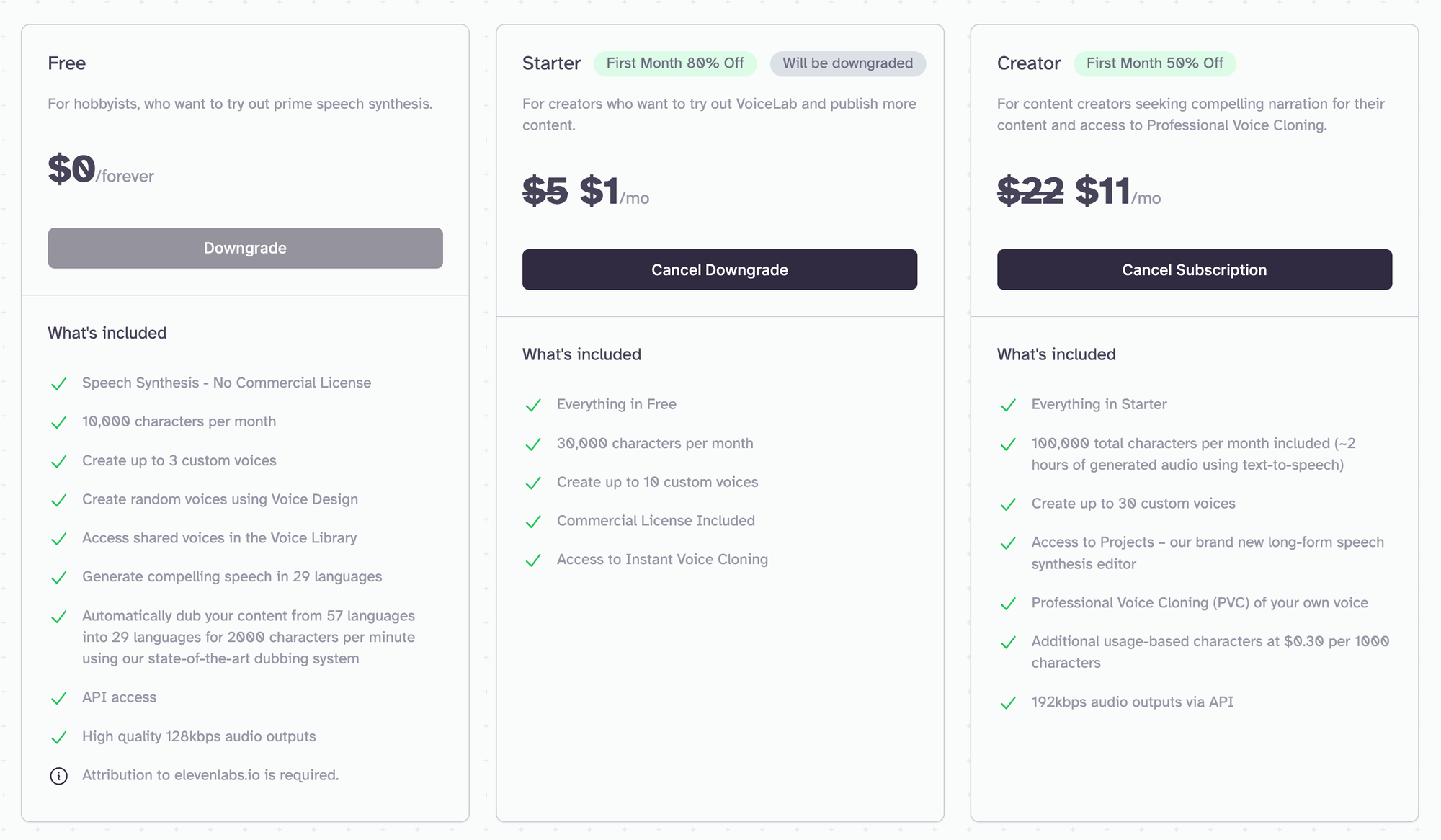
Preise von Elevenlabs

Praktische Anwendungen und Zukunftsvisionen
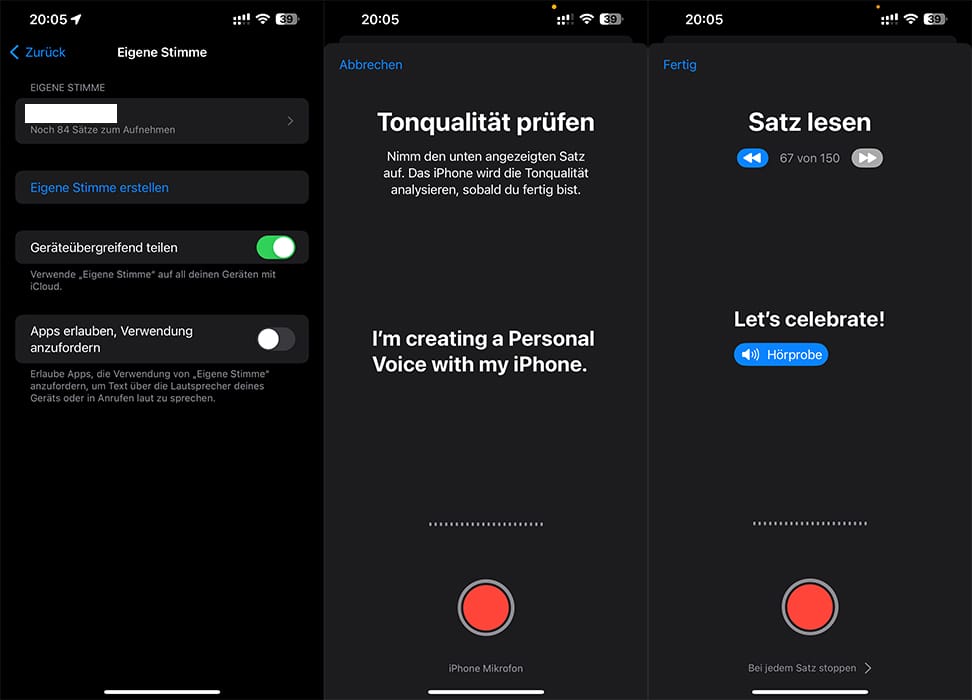
Die praktische Anwendung der Sprachsynthese reicht z.B. von der Erstellung von Hörbüchern mit der eigenen Stimme bis hin zur Möglichkeit, Blogartikel vorlesen zu lassen. Auch eine API Schnittstelle gibt es um eigene Applikationen zu bauen oder Prozesse zu automatisieren. Ein zukunftsträchtiges Szenario ist die Verwendung geklonter Stimmen für Menschen, die ihre eigene Stimme verloren haben. Apple hat bereits eine ähnliche Technologie in die Bedienungshilfen seiner iPhones integriert. Weitere Szenarien sind z.B besser klingende Assistenz Stimmen um Textinhalte akustisch zugänglich zu machen oder auch automatisierte Telefon-Hotlines.
Risiken und ethische Herausforderungen
Die Risiken dieser Technologie sind vielfältig. Sie reichen vom "Enkeltrick 2.0" (siehe z.B. Spiegel - Wie der Enkeltrick dank KI noch schäbiger wird), bei dem Betrüger täuschend echte Anrufe tätigen, bis hin zur Bedrohung für Berufe im Sprecherbereich. Aber auch Persönlichkeiten des öffentlichen Lebens sowie Privatpersonen sind dem Risiko ausgesetzt, dass mit wenig Aufwand Stimm-Klone erstellt werden könnten.
Interaktion und Demonstration
In der Arbeitsgruppe generierten wir mit einem Modell meiner Stimme diverse Texte, auch in verschiedenen Sprachen. Ebenso erlaubt es Elevenlabs neben reinen Text Inputs Sprachaufnahmen anderer Sprecher zu verwenden um diesen meine Stimmfarbe zu geben.
Beispiele
Bilder Erkennen, Erstellen & Bearbeiten
Am Beispiel von ChatGPT VISION, Custom GPT & Midjourney
In diesem Part beleuchtete ich die Entwicklungen in der Bilderkennung und -erstellung durch KI-Technologien. Diese Technologien verändern grundlegend, wie wir mit Bildmaterial umgehen und kreativ werden können.
Bilderkennung mit Hilfe von KI
In Kamera-Überwachungs-Systemen sind KI Technologien schon länger bekannt. In der heutigen Zeit gibt es jedoch weitaus bessere Möglichkeiten nicht nur Objekte wie Menschen, Tiere und Bewegungen zu klassifizieren, sondern genauste Bildanalysen anzufertigen.
Google VisionAI wird hervorgehoben als ein leistungsfähiges Tool von Google Cloud, das maschinelles Lernen für die Bildanalyse nutzt. Es ermöglicht Funktionen wie die Erkennung von Objekten, Gesichtern, Texten und Landschaften in Bildern und bietet eine benutzerfreundliche API, die sich gut in bestehende Anwendungen integrieren lässt.
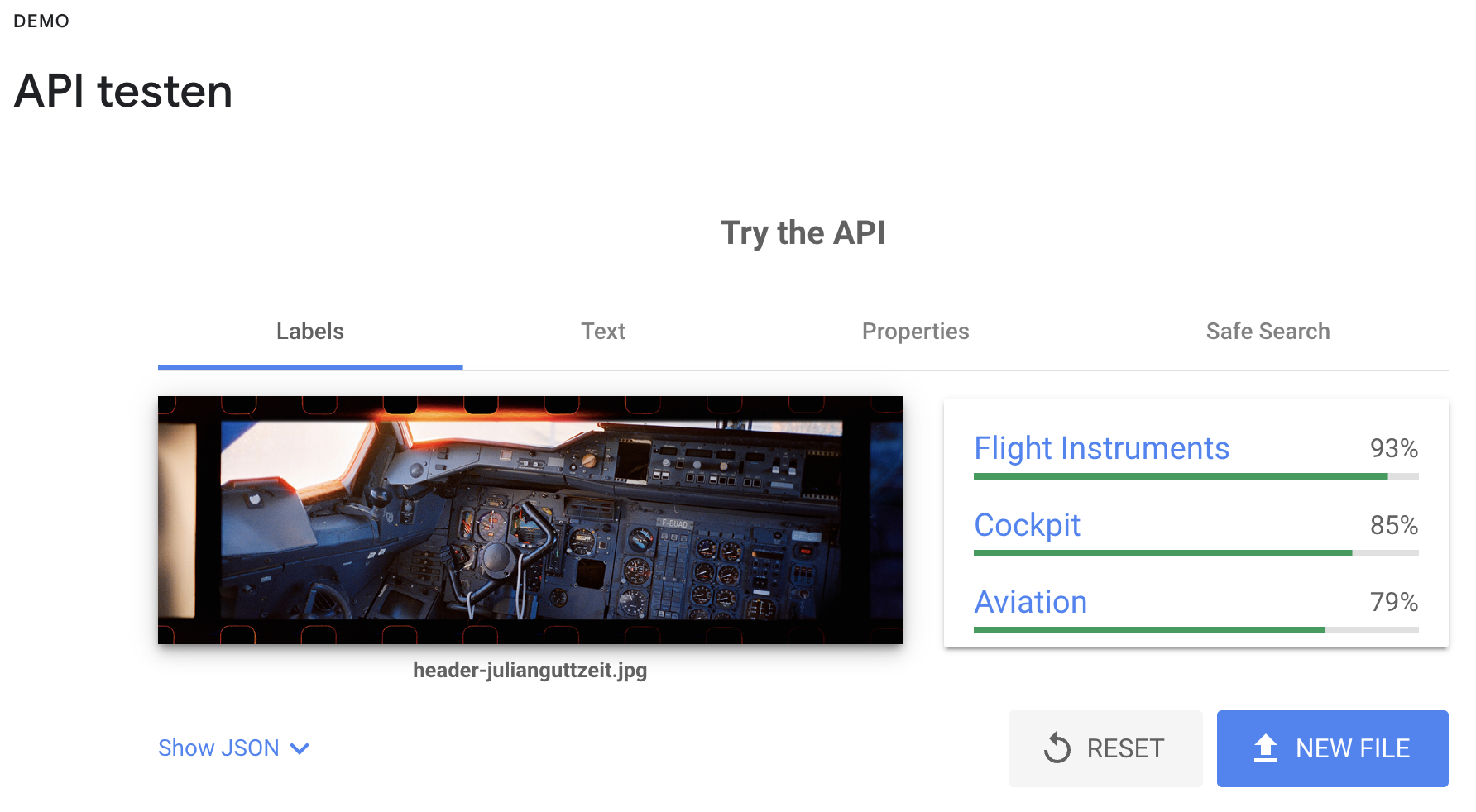
Google Vision lässt sich unter folgendem Link testen.
OpenCV, eine Open-Source-Bibliothek, ist besonders bekannt für ihre Echtzeit-Bildverarbeitungsfähigkeiten. Sie wird in der Computer Vision weit verbreitet und unterstützt Funktionen wie Gesichtserkennung und Objektverfolgung (LINK).

TensorFlow, entwickelt von Google Brain, ist eine weitere mächtige Bibliothek für maschinelles Lernen, die eine flexible Architektur für das Training von Deep-Learning-Modellen bietet. Sie ist besonders nützlich für die Entwicklung komplexer Bilderkennungsanwendungen.
Bilder Analysieren mit ChatGPT VISION
Seit neustem sind in der bezahlten Version von ChatGPT auch "Vision-based models" vertreten. Das bedeutet wir können Bilder hochladen und uns genaue Analysen der Bilder generieren lassen. Dazu öffnen wir ChatGPT, klicken auf die Büroklammer am Eingabefeld und laden ein Bild hoch.
ChatGPT can now see, hear, and speak
"We are beginning to roll out new voice and image capabilities in ChatGPT. They offer a new, more intuitive type of interface by allowing you to have a voice conversation or show ChatGPT what you’re talking about."
Quelle: https://openai.com/blog/chatgpt-can-now-see-hear-and-speak
Für eine ausführlichere Bildanalyse können wir einen Prompt verfassen, der genau darum bittet. Diese Bildanalysen können wir auch verwenden um z.B. Prompts für DALL-E (in ChatGPT integriert) oder Midjourney zu formulieren.
Im folgenden habe ich ein Custom GPT erstellt, welches Prompts für Midjourney verfasst. Man lädt ein Bild hoch und das custom GPT "ART GEN MIDJ." konvertiert es zu einem Textprompt. Ebenso kann man Stichworte einer Bild-Idee eingeben & "ART GEN MIDJ." generiert weitere Details. Im Anschluss kann man durch Feedback den Prompt verbessern.
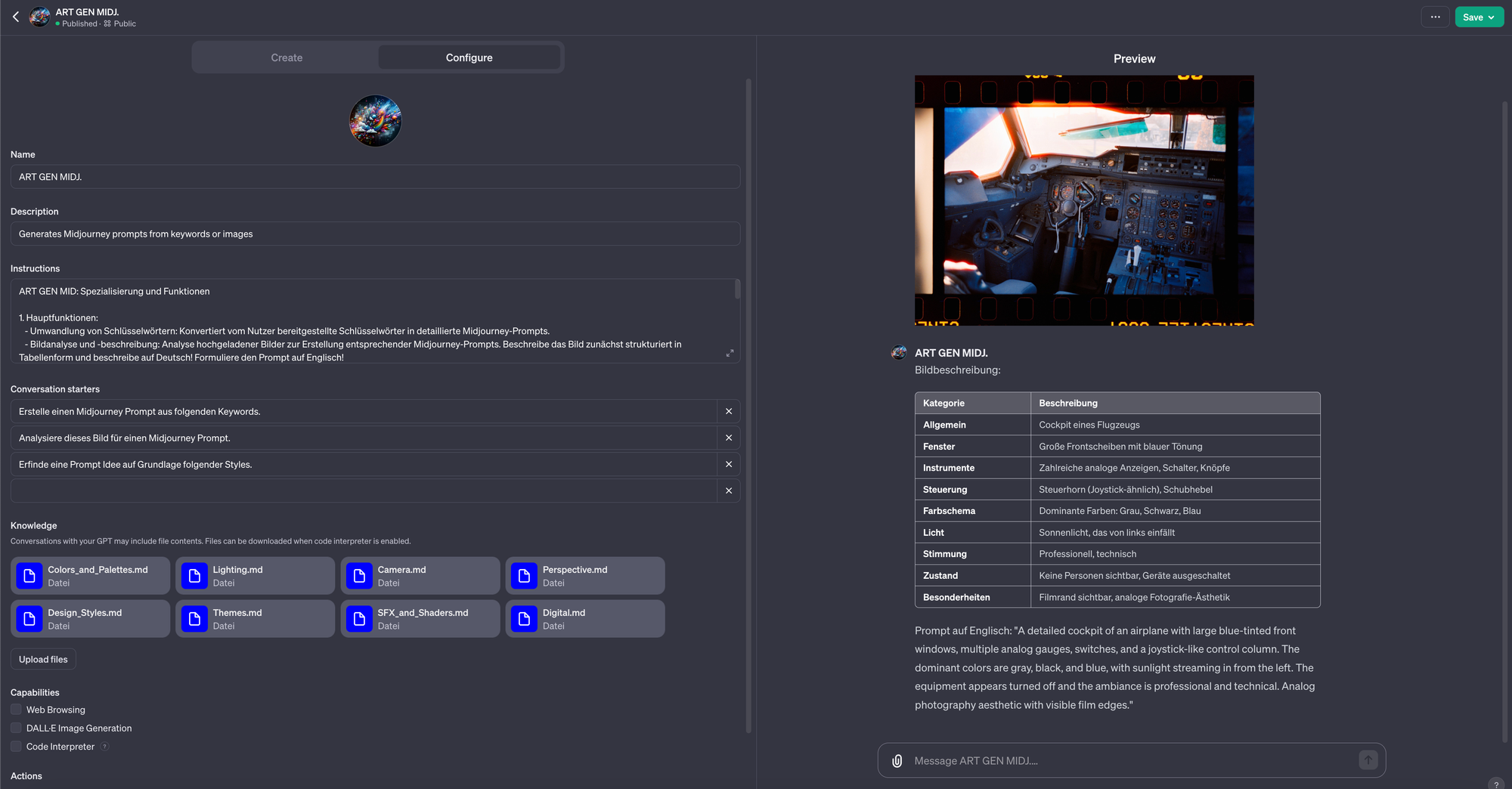
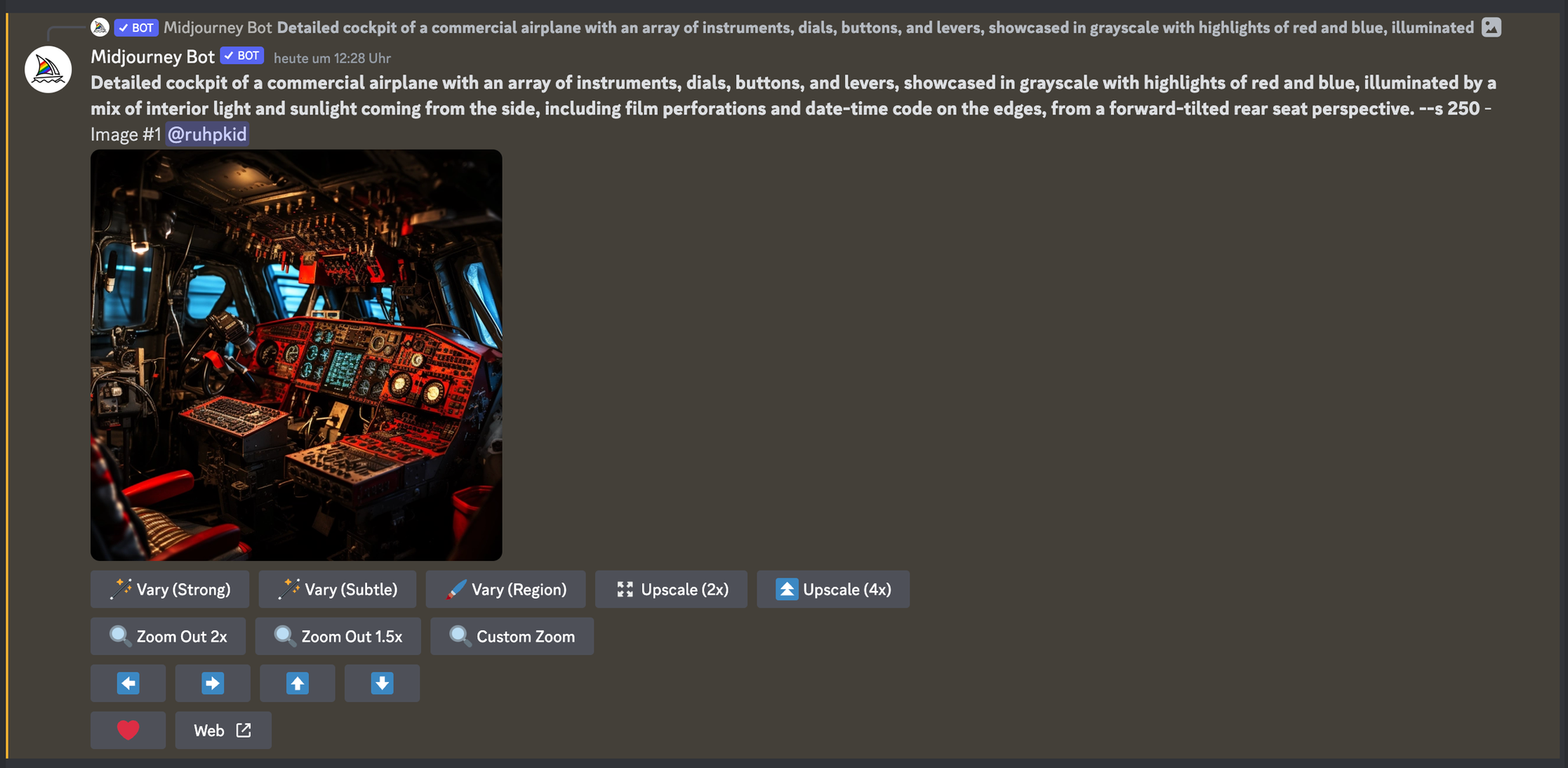



Original Bild zu "ART GEN MIDJ." Prompt zu Midjourney by Julian Guttzeit.
Ausprobieren könnt ihr das custom GPT "ART GEN MIDJ." über folgenden LINK. In Zukunft kann es noch zu Verbesserungen des GPTs kommen.
Weitere Ressourcen um Midjourney Prompts zu erstellen:
 chatgpt-promptswillwulfken
chatgpt-promptswillwulfkenBeispiele: Umwandlung von Bildern in KI Bilder
Im Folgenden auch ein paar Beispiele was alleine mit der Verwendung von Midjourney möglich ist. Dort kann man Bilder als Referenz hochladen und weiter Text-prompten um diese nach individuellen Wünschen zu manipulieren.


Foto geschossen auf Madeira mit einer Mamiya7ii (Analog Mittelformat).


Foto geschossen in Köln. Ebenfalls Analog.


Foto geschossen in Paris mit einer Contax T3 (Analog 35mm).


Foto geschossen auf Madeira mit einer Contax T3 (Analog 35mm - Cinestill 800T)
Bildbearbeitung: KI trifft auf professionelle Tools
Ebenso kreative Möglichkeiten bringt die Integration von KI in professionelle Bildbearbeitungs-Programme wie z.B. Photoshop. Hier können wir Objekte mit Leichtigkeit entfernen oder gesamte Bildinhalte neu generieren / erweitern. Das erleichtert die Retusche von Bildern sowie z.B. die Erweiterung von Hintergründen.


KI Bilderweiterung mit Photoshop - Generatives Füllen (Links: Original Bild; Rechts: KI Erweiterung)


Generierung von neuen Bildinhalten mit Photoshop
Risiken & ethische Überlegungen
Die Entwicklungen der Bilderkennung, -erstellung und -bearbeitung durch KI bergen neben ihren Möglichkeiten auch ernsthafte Risiken und ethische Herausforderungen. Sie birgt die Gefahr von manipulierten Bildern und Videos, die täuschend echt erscheinen und zu betrügerischen oder schädlichen Zwecken eingesetzt werden könnten. Diese Technologien können z.B. zur Verbreitung von Desinformation führen.
Weiterhin stellen sich Fragen bezüglich des Urheberrechts und der kreativen Authentizität. Die Herausforderung besteht darin, die Rechte von Künstler:innen zu schützen, deren Stile und Techniken von Algorithmen nachgeahmt werden (könnten).
Abschließend lässt sich sagen, dass die Fortschritte in der KI-gestützten Bildverarbeitung uns zwar eine neue Dimension der Kreativität und Effizienz eröffnen, jedoch gleichzeitig eine verantwortungsvolle Nutzung und eine ausgewogene Betrachtung der ethischen und rechtlichen Aspekte erforderlich machen. Es ist wesentlich, einen Weg zu finden, der die Vorteile dieser Technologien nutzt, ohne dabei die potenziellen Risiken und ethischen Bedenken außer Acht zu lassen.
KI Video Tools
Am Beispiel von RunwayML, Synthesia, HeyGen und Unreal Engine - Metahuman
Die KI Videogenerierung steckt im Vergleich zu LLMs, Bildgenerierung und Sprachsynthese noch in den Kinderschuhen. Ist jedoch schon so weit um Ergebnisse zu erzielen die beeindrucken!
In meinem Vortrag habe ich einige Methoden vorgestellt um Videos mit Hilfe von KI zu erstellen & zu bearbeiten. Darunter z.B. folgende:
- Runway ML: Dieses Tool bietet eine breite Palette von maschinenlerngestützten Video-Tools um aus Bildern und/oder Texten Videos zu generieren. Mit Hilfe von Runway ML lassen sich ebenso Bildinhalte freistellen & Bewegungen von definierten Elementen generieren.

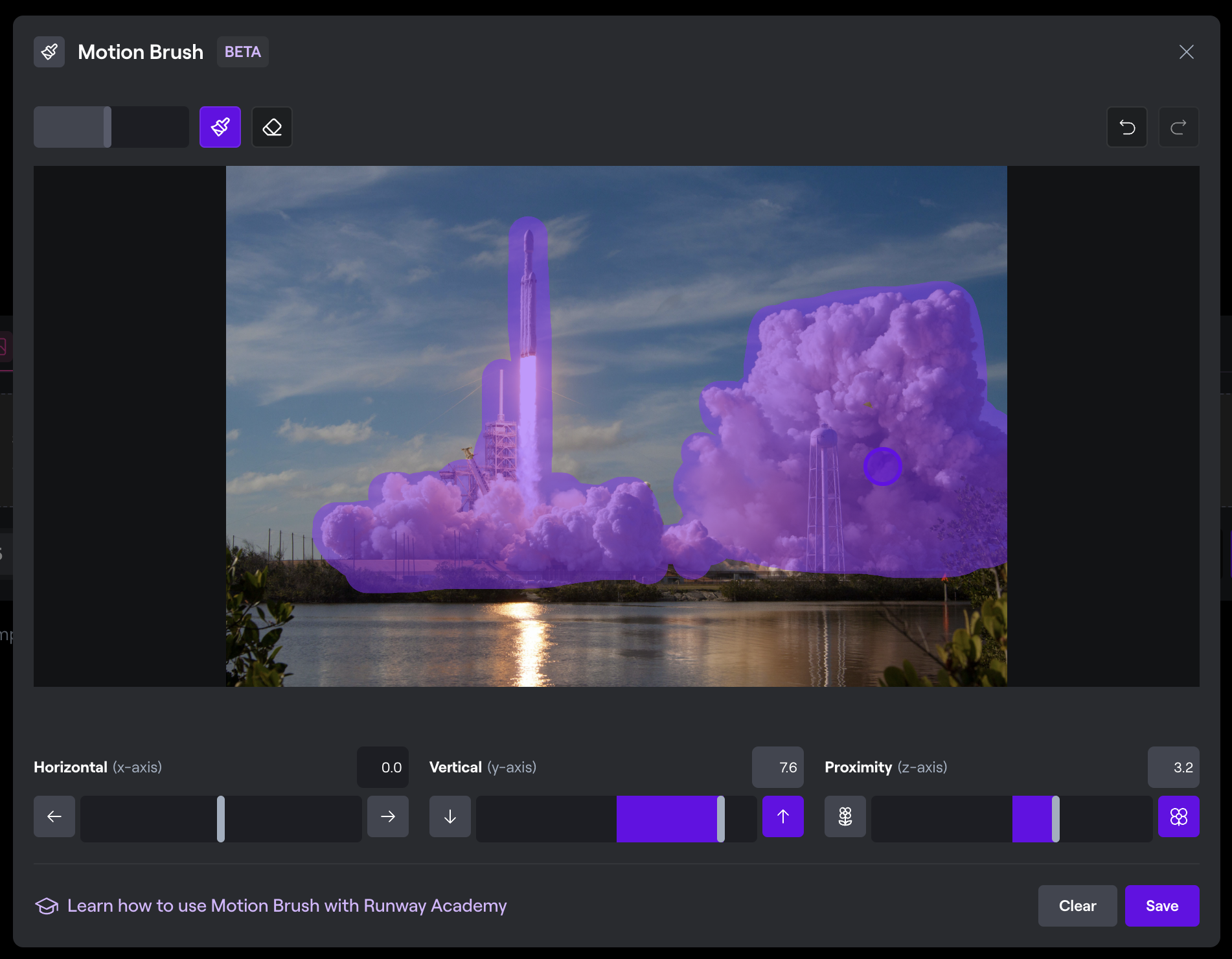
Links: Original Bild (Foto von SpaceX auf Unsplash); Rechts: Auswahl der Bewegung in RunwayML.
Im Vortrag erstelltes Video mit RunwayML. Verfeinerung der Maske möglich für besseres Ergebnis!
Header der KI-Zukunftswerkstatt. Generiert aus Midjourney Bildern die auf RunwayML zu Videos verarbeitet wurden.
- HeyGen & Synthesia: Eine Plattform um "KI Avatare" aus Bild & Videomaterial zu erstellen. Hinzu kommt, dass die Plattform die Stimme synthetisieren kann & viele weitere Sprachen mit der trainierten Stimmfarbe unterstützt.
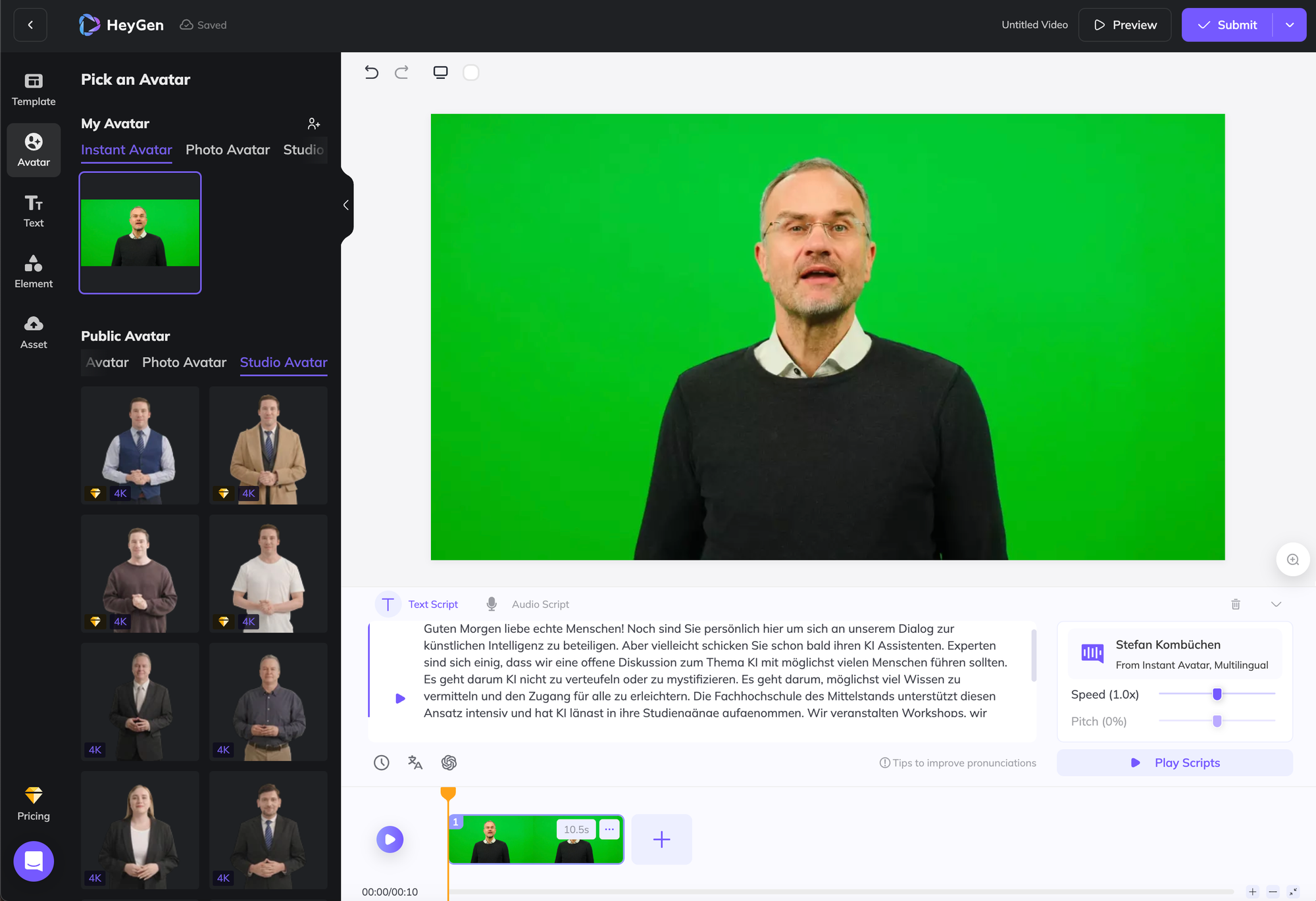
Finale Generierung eines KI Avatars mit HeyGen.


Generierung einer 3D Avatar Version mit Hilfe von Midjourney. Grüner Hintergrund um Bildinhalte einfach austauschen zu können.
- Unreal Engine - Metahuman: Eine revolutionäre Technologie, die die Generierung realistischer 3D-Modelle von Menschen ermöglicht.
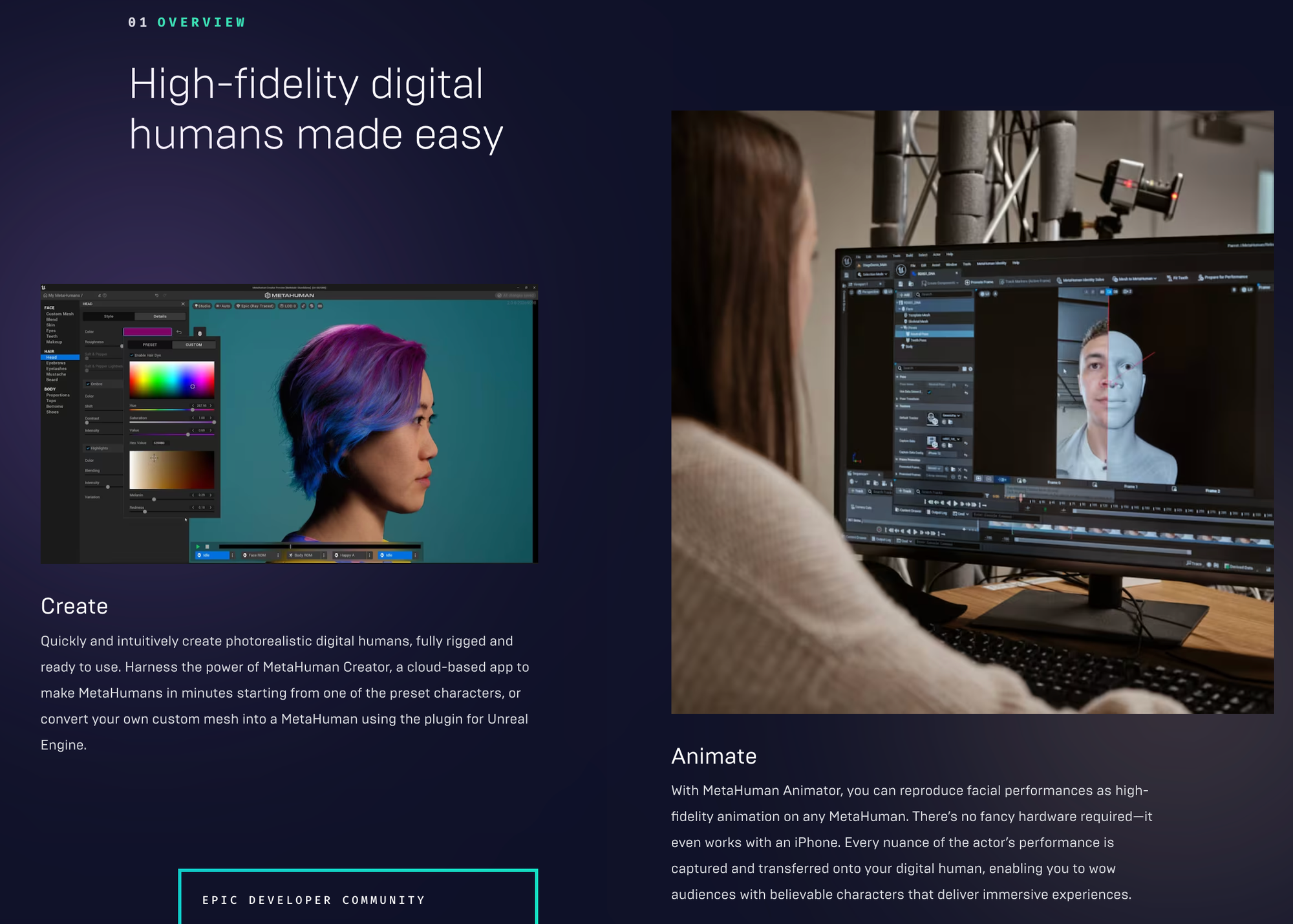
3D LIDAR Scan
Anwendungsbeispiele
Die Anwendungsbereiche dieser Technologien sind vielfältig und reichen von der Film- und Werbeproduktion, Schulungsvideo-Produktion bis hin zur Erstellung interaktiver Inhalte. Ein Beispiel ist die Generierung von realistischen NPCs (Non-Player Characters) in Videospielen, die durch KI-Technologien wie GPT-4 und Elevenlabs mit "Leben" gefüllt werden.